
Async Await - 1
Intro
오늘은 Swift 5.5에서 추가된 Async/Await에 대해서 알아보려고 한다.
거창하게 이걸 어디 어떻게 사용해야하고 이런거 보다는 이번 포스트에서는 어떤 식으로 이게 굴러가는지부터 알아보려 한다.
오늘 포스트는 Async Await 프로포절과 Swift 릴리즈 노트를 기준으로 작성하였다.
배경
Async Await에 대해 알려면 어떤 배경으로 추가되었는지 알아야 한다.
Async Await은 비동기 프로그래밍과 관련이 깊다.
기존 Swift에서도 비동기 프로그래밍을 지원하기 위해서 클로저나 completion handler를 제공하고 있었다.
어떤 문제점들이 있기에 Async Await이 도입되었을까?
프로포절에는 다음과 같은 문제점들이 나와 있다.
- 비동기 작업이 많아지거나
- 에러 처리가 필요하거나
- 비동기 코드 호출 간의 제어 흐름이 복잡해질 때
기존의 방식은 복잡도가 올라가고 그에 따라 디버깅도 어려워진다.
기존의 문제점
사실 이런 문제점을 봤을때 기존의 코드에 적응했어서 그런가 그렇게까지 큰 문제인가? 라는 생각이 먼저 들긴 했다;
그럼 예시들을 보면서 어떤 문제점이 있는지 확인해보자.
Pyramid of doom
func precessImageData1(completionBlock: (_ result: Image) -> Void) {
loadWebResource("dataprofile.txt") { dataResource in
loadWebResource("imagedata.dat") { imageResource in
decodeImage(dataResource, imageResource) { imageTmp in
dewarpAndCleanupImage(imageTmp) { imageResult in
completionBlock(imageResult)
}
}
}
}
}
프로포절에 있던 예시 코드이다.
보고 처음에 들었던 생각은 depth가 너무 깊고 코드가 잘 안 읽혔다.
코드를 차근차근 뜯어보면
- 텍스트 리소스를 가져오고
- 이미지 리소스를 가져와
- 이미지를 디코딩 한 후
- 그 결과를 재가공 후
- completionBlock(completion handler)를 호출
해주고 있다.
이런 5가지의 과정을 중첩 클로저로써 표현하고 있다.
그럼 이런 코드의 문제점은 뭘까?
이런 코드는 실행되는 위치를 읽기 어렵게 만든다.
그에 따라 코드를 추적하기 어렵게 만든다.
그에 따라 코드의 복잡도가 올라가고 디버깅 또한 힘들어진다.
Error handling
그렇다면 에러 핸들링 측면에서는 어떨까?
func processImageData2a(completionBlock: (_ result: Image?, _ error: Error?) -> Void) {
loadWebResource("dataprofile.txt") { dataResource, error in
guard let dataResource = dataResource else {
completionBlock(nil, error)
return
}
loadWebResource("imagedata.dat") { imageResource, error in
guard let imageResource = imageResource else {
completionBlock(nil, erorr)
return
}
decodeImage(dataResource, imageResource) { imageTmp, error in
guard let imageTmp = imageTmp else {
completionBlock(nil, error)
return
}
dewarpAndCleanupImage(imageTmp) { imageResult, error in
guard let imageResult = imageResult esle {
completionBlock(nil, error)
return
}
completionBlock(imageResult)
}
}
}
}
}
에러를 처리하기 위해 nil을 주입한 result와 error를 completion handler에 실어서 내보내고 있다.
한 눈에 봐도 코드가 굉장히 길고 한 눈에 안 읽힌다.
그렇다면 비교적? 최근에 나온 Result 타입을 사용한다면 어떨까?
func processImageData2b(completionBlock: (Result<Image, Error>) -> Void) {
loadWebResource("dataprofile.txt") { dataResourceResult in
do {
let dataResource = try dataResourceResult.get()
loadWebResource("iamgedata.dat") { imageResourceResult in
do {
let imageResource = try imageResourceResult.get()
decodeImage(dataResource, imageResource) { imageTmpResult in
do {
let imageTmp = try imageTmpResult.get()
dewarpAndCleanupImage(imageTmp) { imageResult in
completionBlock(imageResult)
}
} catch {
completionBlock(.failure(error))
}
}
} catch {
completionBlock(.failure(error))
}
}
} catch {
completionBlock(.failure(error))
}
}
}
Result 타입이 에러 처리를 개선해줬기는 했지만 클로저 중첩에 대한 문제점은 그대로 남아 있다.
Many mistakes are easy to make
에러 상황에서 completaion handler를 호출하지 않고 바로 return 처리하는 것도 문제이다.
func processImageData4a(completionBlock: (_ result: Image?, _ error: Error?) -> Void) {
loadWebResource("dataprofile.txt") { dataResource,error in
guard let dataResource = datraResource else {
// 🤔
return
}
loadWebResource("imagedarta.dat") { imageResource, error in
guard let imageResource = imageResource else {
// 🤔
return
}
...
}
}
}
위에서 주석 🤔 부분을 확인해보면 guard 문에서 else로 빠지는 완벽한 에러 상황이지만 에러 처리를 하지 않고 바로 return을 한다.
이렇게 처리하는게 사실상 에러 처리를 위한 코드를 줄일 수도 있고 개발자 입장에서는 좀 더 편한 처리 방식일수는 있다.
그렇지만 만약 🤔 해당 부분에서 에러가 발생했다면 디버깅하기 어려워진다.
그래서
기존의 비동기 코드가 갖는 문제점들을 살펴봤다.
정리하자면
- 비동기 코드가 중첩될 경우 실행되는 위치를 알기 어렵다.
- 에러 처리가 어렵고 장황하다.
- Completion handler 호출을 잊을 수도 있다.
라는 문제점들이 있다.
사실 이런 문제점들은 하나로 귀결된다.
코드의 가독성을 떨어트리고 디버깅을 어렵게 한다.
Async Await
그럼 이런 문제점들 위에 등장하게 된 Async Await은 기존의 방식들과 얼마나 다른 모양일까?
func loadWebResource(_ path: String) async throws -> Resource
func decodeImage(_ r1: Resource, _ r2: Resource) async throws -> Image
func dewarpAndCleanupImage(_ i: Image) async throws -> Image
func processImageData() async throws -> Image {
let dataResource = try await loadWebResource("dataprofile.txt")
let imageResource = try await loadWebResource("imagedata.dat")
let imageTmp = try await decodeImage(dataResource, imageResource)
let imageResult = try await dewarpAndCleanupImage(imageTmp)
return imageResult
}
위에서 예시로 살펴본 코드를 Async Await으로 구현한 코드이다.
굉장히 간결해지고 가독성도 올라갔다.
프로포절에 의하면 Async Await을 사용하면 비동기 코드를 동기 코드인 것처럼 작성할 수 있다고 한다.
async, await 키워드를 제외하면 동기 코드처럼 보인다.
위에서 살펴본 문제점들을 다시 살펴 본다면
- 비동기 코드가 중첩될 경우 실행되는 위치를 알기 어렵다.
- 에러 처리가 어렵고 장황하다.
- Completion handler 호출을 잊을 수도 있다.
현재 코드에서는 중첩될 일이 없어 보인다.
기존에 사용하던 throws를 통해 깔끔하게 에러 처리가 가능한거 같다.
Async Await의 특징 중 하나는 작업이 종료될 때 completion handler 호출을 하지 않아도 작업 종료를 알려주는걸 보장해준다.
Proposed
Swift 5.5 릴리즈 노트에 있는 예시로 한 번 알아보자.
func listPhotos(inGallery name: String) async -> [String] {
let result = // ...some asynchronous networking code ...
return result
}
func showFirstPhoto() async {
let photoNames = await listPhotos(inGallery: "Summer Vacation")
let sortedNames = photoNames.sorted()
let name = sortedNames[0]
let photo = await downloadPhoto(named: name)
show(photo)
}
위의 코드는 갤러리에 있는 사진을 모두 가져와 이름순으로 정렬한 후 첫번째 사진을 보여주고 있다.
listPhotos()나 downloadPhoto()는 완료하는데 시간이 오래 걸릴 수 있는 작업이다.
따라서 Async를 사용해 비동기 메서드로 만든다면 해당 코드의 완료를 기다리는 동안 앱의 다른 코드가 실행될 수 있다.
showFirstPhoto() 메서드의 실행 순서를 살펴보자.
릴리즈 노트에 따르면 해당 메서드는 코드의 첫 줄부터 첫번째 await까지 실행된다고 한다.
await으로 listPhoto()를 호출하고 해당 함수가 반환될 때까지 showFirstPhoto()의 실행은 일시 중단(suspends execution)된다.
해당 코드가 일시 중단되는 동안 다른 동시 코드들이 실행된다.
listPhotos()가 반환된 후 중단된 지점(continues execution)부터 다시 실행된다.
sortedNames나 name 프로퍼티는 일반 동기 코드로 await이 없기 때문에 실행 중지 지점이 없다.
downloadPhoto에는 await이 있기 때문에 listPhotos와 동일하게 해당 메서드가 반환될 때까지 실행을 다시 중지한다.
await
위에서 살펴본 예시에서 반복되는 단어들이 있다.
await, 중단(suspend)이다.
프로포절에 따르면
The possible suspension points in your code amrked with await
await은 suspension point를 표기한 키워드라고 한다.
suspension point는 비동기 메서드가 반환되기를 기다리는 동안 현재 코드 부분의 실행이 일시 중지될 수 있음을 나타내는 지점이다.
This is also called yielding the thread
이를 다른 말로는 스레드 양보라고도 한다.
현재 스레드에서 코드 실행을 일시 중단하고 해당 스레드에서 다른 코드를 실행하기 때문에 이렇게 불린다고 한다.
Thread
그렇다면 스레드 양보가 무엇인지 알아볼 필요가 있다.
WWDC 영상을 활용하면서 알아보자.
Sync
비동기에서의 스레드 처리를 알아보기 전에 동기 코드에서 스레드가 어떻게 이용되는지부터 알아보자.
동기 함수는 호출되면 호출이 완료될 때까지 기다린다.
호출이 완료되면 제어 기능이 함수로 돌아가 중단된 부분부터 다시 시작하게 된다.

편의상 fetchThumbnail을 A라고 thumbnailURLRequest를 B라고 지칭하자.
A가 동기 메서드 B를 호출하면 A가 실행되던 스레드 컨트롤이 B에게 전달된다.
B는 해당 스레드를 선점하게 되어 다른 코드들은 실행될 수 없다.
B의 실행이 끝나면 A에게 스레드 컨트롤을 돌려 준다.
Async
그렇다면 비동기 함수를 호출한다면 어떻게 될까?
프로포절에는 비동기 함수는 스레드를 포기할 수 있는 특별한 능력을 가진 일반 함수로 생각하라는 문장이 있다.
이를 생각하면서 한 번 봐보자.
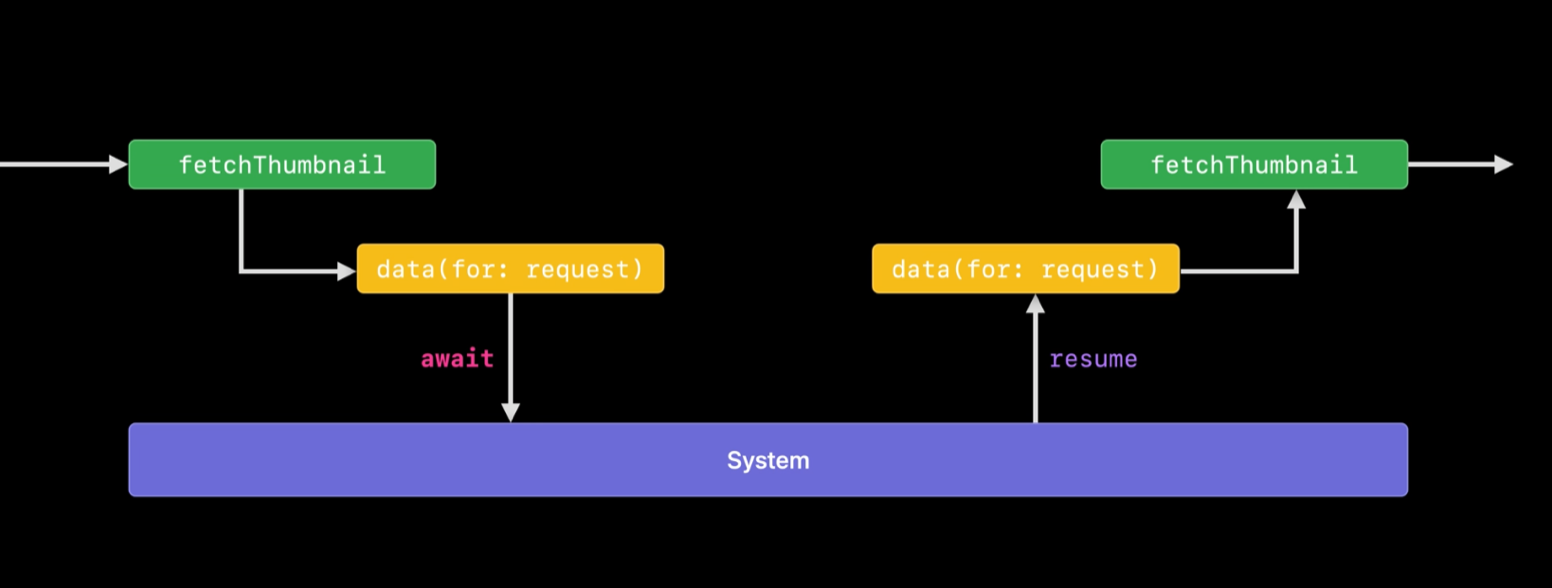
편의상 fetchThumbnail을 A라고 data(for: _)을 B라고 지칭하자.
여기서는 A가 비동기 메서드 B를 호출했다.
동기 함수와 마찬가지로 A가 실행되던 스레드 컨트롤이 B에게로 전달된다.
B의 실행이 끝나면 A에게 스레드 컨트롤을 돌려준다.
사실상 이런 과정은 동기 함수의 실행 과정과 다른게 없다.
하지만 비동기 함수는 스레드를 포기할 수 있다고 했다.
즉, B는 비동기 함수로써 스레드를 포기할 수 있다.
여기서 스레드를 포기한다는 것은 스레드 컨트롤을 포기한다는 뜻과 동일하고 suspend되었다고 한다.
위에서 await은 suspension points를 표기한거라고 했는데요.
그렇다면 await은 잠재적으로 여기서는 스레드를 포기할 수 있다고 알려주는거라고 할 수 있다.
B 함수가 스레드를 포기==스레드 컨트롤을 포기==suspend되면 이를 호출한 A도 suspend된다.
A가 비동기 함수 B를 호출했다.
suspension point인 await을 만났으니 스레드 컨트롤을 포기한다.
스레드를 포기했으므로 해당 async 작업이나 같은 코드 블록 속 코드들은 바로 실행되지 못한다.
여기서 포기한 스레드 컨트롤은 시스템으로 넘어가고 있다.
시스템은 스레드 컨트롤을 받음으로써 해당 async 작업을 실행할 역할을 갖게된다.
이때 시스템은 바로 async 작업을 실행하는게 아닌 우선순위에 따라 시스템에게 주어진 작업을 실행한다.
시스템이 정한 우선순위대로 작업들이 실행되다 해당 async 작업(여기서는 B)의 차례가 오면 resume된다.
resume될 때 스레드 컨트롤을 돌려주게 되는데 처음 B가 실행되던 스레드와 다를 수 있다.
(같을 수도 있고)
그래서 어떤 일이 일어나고 있는데?
모든 스레드는 함수 호출 상태를 저장하기 위해 하나의 Stack을 가지고 있다.
sync
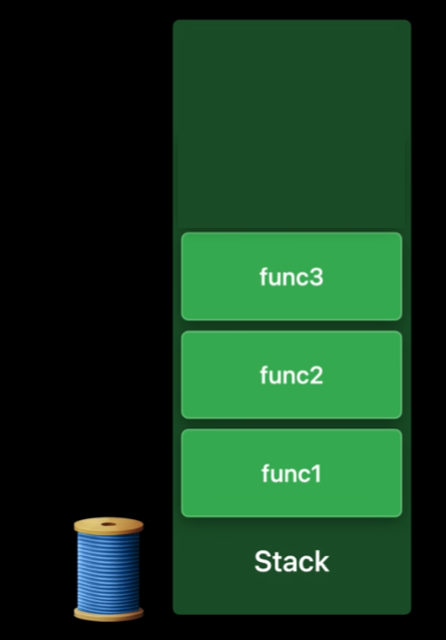
익명의 스레드는 위와 같은 Stack 상태를 가지고 있다고 가정하자.
우리가 func4라는 메서드를 호출한다면
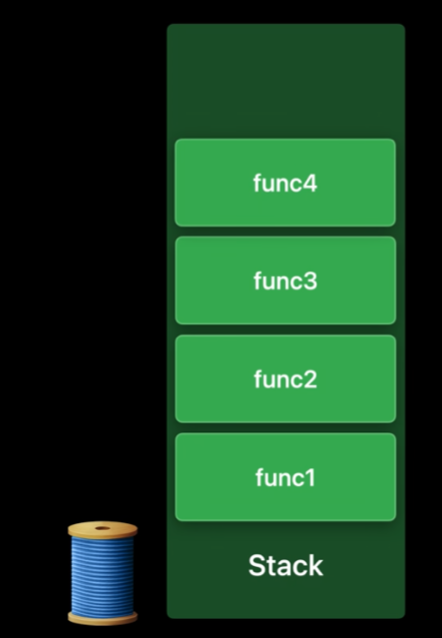
이렇게 Stack에 새로운 프레임이 Push된다.
함수의 실행이 끝나면 해당 프레임이 Stack에서 Pop된다.
사실 이런 형태는 동기 함수일 때에는 별 문제되지 않는다.
A가 B를 호출하면 어차피 해당 스레드는 선점당할테고 해당 스레드에서는 A-B…에 관련된 함수들만 저장될 것이다.
따라서 실행이 완료되어 func4가 Pop된 후, Stack의 top 프레임인 func3에 접근해 중지 지점에서 바로 실행을 재개할 수 있다.
그렇다면 비동기 함수는 어떤가?
async
func add(_ newArticles: [Article]) async throws {
let ids = try await database.save(newArticles, for: self)
for (id, article) in zip(dis, newArticles) {
articles[id] = article
}
}
func updateDatabase(...) async {
await feed.add(articles)
}
이 코드를 예시로 한 번 알아보자.
updateDatabase()에서 add를 호출하니 add()도 Stack에 push 된다.

add()에는 await이 있으므로 하나의 suspension point가 존재한다.
add()의 for문에서 사용되는 id, article은 해당 코드 블럭에서 사용되는 로컬 변수이므로 add 프레임에 저장된다.
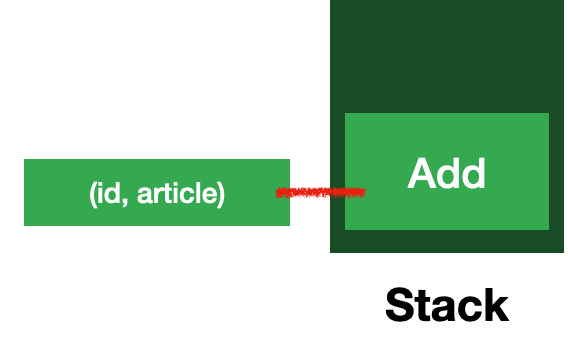
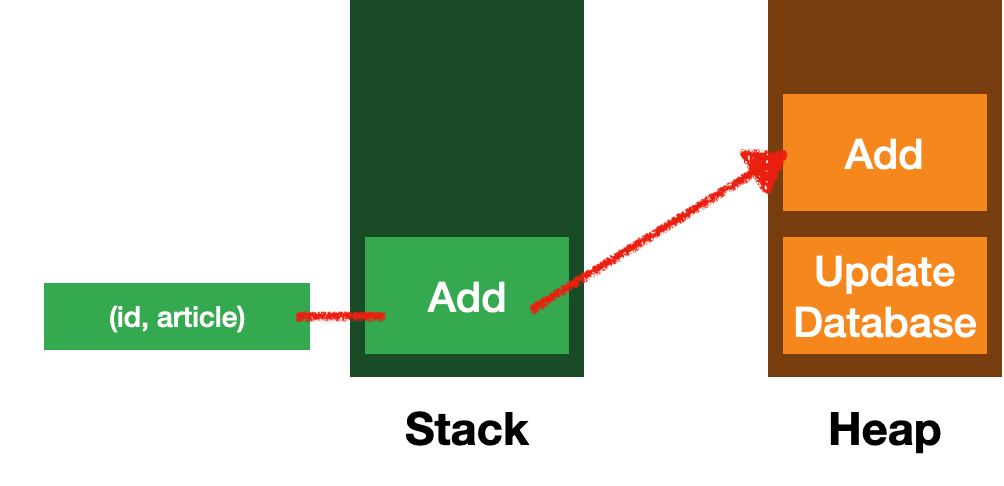
두개의 비동기 프레임이 있는 Heap이 있다.
힙에 저장된 updateDatabase와 add는 모두 await으로 호출되고 있다.
await은 suspension point로 스레드를 포기할 수 있음을 나타낸다.
그렇다면 스레드 포기와 Heap은 무슨 상관이 있을까?
add 메서드가 suspended(일시 중지)된다면 해당 스레드 컨트롤을 포기한다.
스레드 컨트롤을 포기하고 시스템에게 컨트롤을 넘김으로써 해당 스레드가 다른 작업을 실행할 수 있는 상태로 만든다.
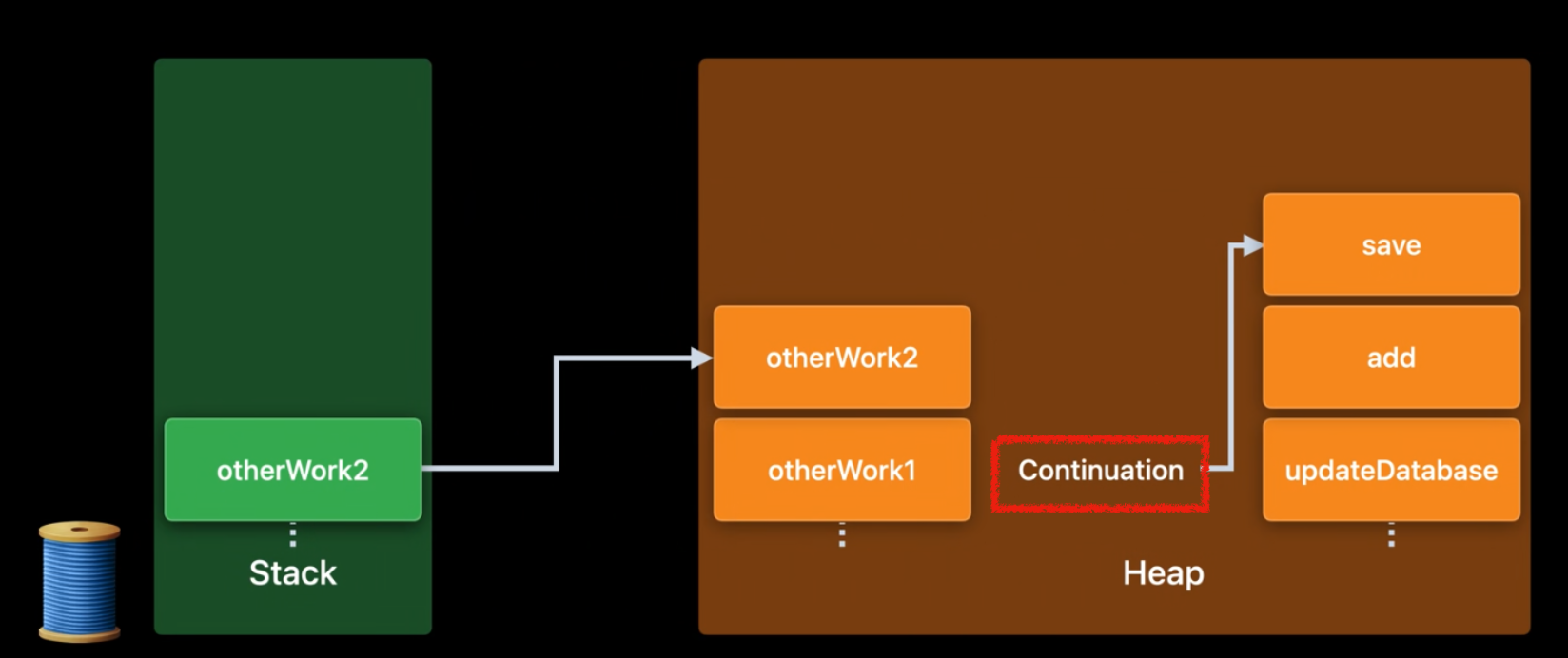
그럼 이런식으로 suspended된 비동기 코드는 힙에 저장되고 해당 스레드에서는 다른 작업(otherWork2)를 실행할 수 있게 된다.
Suspension Point에서 유지되는 모든 정보는 Heap에 저장되고 비동기 메서드가 resume될 때 사용할 수 있다.
WWDC에서는 힙에 저장된 비동기 프레임을 continuation에 대한 런타임 표현이라고 말한다.
continuation은 비동기 호출 후에 일어나는 일로 await 호출 아래의 모든 것을 continuation이라고 한다.
그렇다면 continuation이 생긴 배경은 뭘까?
func beginOperation(completion: (OperationResult) -> Void)
이처럼 콜백을 사용하는 비동기 메서드가 있다.
Swift에서는 종종 콜백을 통해 비동기 코드 실행을 제공했다.
Async Await이 도입되기 전에 코드 자체가 작성되었거나 이벤트 중심인 다른 시스템과의 연결로도 이런 코드가 있을 수 있다.
이런 경우 내부적으로 콜백을 사용하는 동안 클라이언트에 비동기 인터페이스를 제공할 수 있어야 한다.
즉, 비동기 작업은 자체적으로 일시 중단될 수 있어야 하는 동시에 이벤트 기반 동기 시스템이 이벤트에 대한 응답으로 작업을 재개할 수 있도록 해야한다.
이를 가능하게 해주는 것이 continuation이다.
Swift에서는 현재 비동기 작업에 대한 continuation을 얻기 위한 API들을 제공한다.
작업의 continuation을 가져오면 작업이 일시 중단되고 동기 코드에서 작업을 재개할 수 있는 값이 생성된다.
await을 만나면 실행이 일시 중단되고 Heap에 비동기 프레임이 생성된다.
일시 중단되었을때 가장 큰 특징은 스레드 컨트롤을 포기하고 이를 시스템에게 넘긴다는 점이다.
그럼 우리가 위에서 살펴 봤던 특징들을 종합해보자.
-
스레드는 함수 호출 상태를 저장하기 위해 하나의 Stack을 가지고 있다.
-
메서드가 호출되면 stack에 해당 메서드 프레임이 push된다.
await을 만나면 실행이 일시 중단이 되고 해당 스레드 컨트롤을 포기한다.- 스레드 컨트롤을 포기하면 해당 함수 호출 상태를 저장한 Stack 또한 포기한다.
시스템에 의해 해당 비동기 메서드가 resume 될때 어느 지점에서 실행 재개 되어야 하는지 어떻게 알 수 있을까?
이때 continuation가 필요해진다.

이렇게 Heap에는 continuation 리스트들이 저장되게 되고 resume을 하면 이 리스트들에서 Continuation을 꺼내서 작업을 재개한다.
이를 좀 더 자세하게 본다면

이렇게 스레드가 해제되었을 때 Heap에 있는 비동기 프레임이 resume될 수 있다.
해제된 스레드는 이전과 동일한 스레드일수도 아닐 수 도 있지만 중지되었던 포인트를 알고 있기 때문에 해당 포인트부터 다시 작업을 실행할 수 있다.
Outro
Async Await에서 살짝 핥아만 봤다.
사실상 Async Await보다는 스레드 운영에 좀 더 초점이 맞춰져 있지만…
이런거를 이해하고 있어야 이후 스텝도 이해하기 쉽지 않을까 해서 포스팅해본다.
Leave a comment